Thirteen years after its first release…
… after countless feature requests…
… experiencing dead and dying web development frameworks…
… acknowledging new and useful web development technology…
… and evolving best practices for DH tool development…
we are rewriting Stemmaweb from the ground up. We are aiming for a release by the end of 2025.
Rationale
Like many software applications in the humanities, the development and maintenance of Stemmaweb must be managed on a shoestring, and sustainability is hard, as we have all learned. Since Stemmaweb’s inception, maintainers (this means, by and large, Tara and Joris) have struggled to keep up with functional demand and the minimally required maintenance regarding platform upgrades, security requirements, and bug fixes. While the introduction of a new data repository system bought us some time, it has been increasingly clear over the last five to seven years that Stemmaweb has been in dire need of both backend and frontend upgrades.
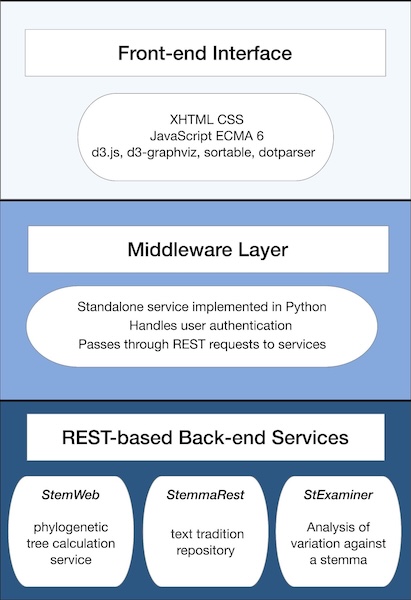
Given the low-resource nature of running Stemmaweb, we have chosen lightweight standards wherever possible. To maximize sustainability and maintainability, the rewritten Stemmaweb uses only pure JavaScript libraries, HTML5 and CSS in the front end, no web frameworks or transpiled code. The Flask-based middleware is designed to pull together the variety of backend services from different authors, upon which Stemmaweb relies for its functionality. We have also carried out a major refresh of the user interface, in line with modern UI/UX guidelines, to give users a more inviting and intuitive experience of the tools.
Features
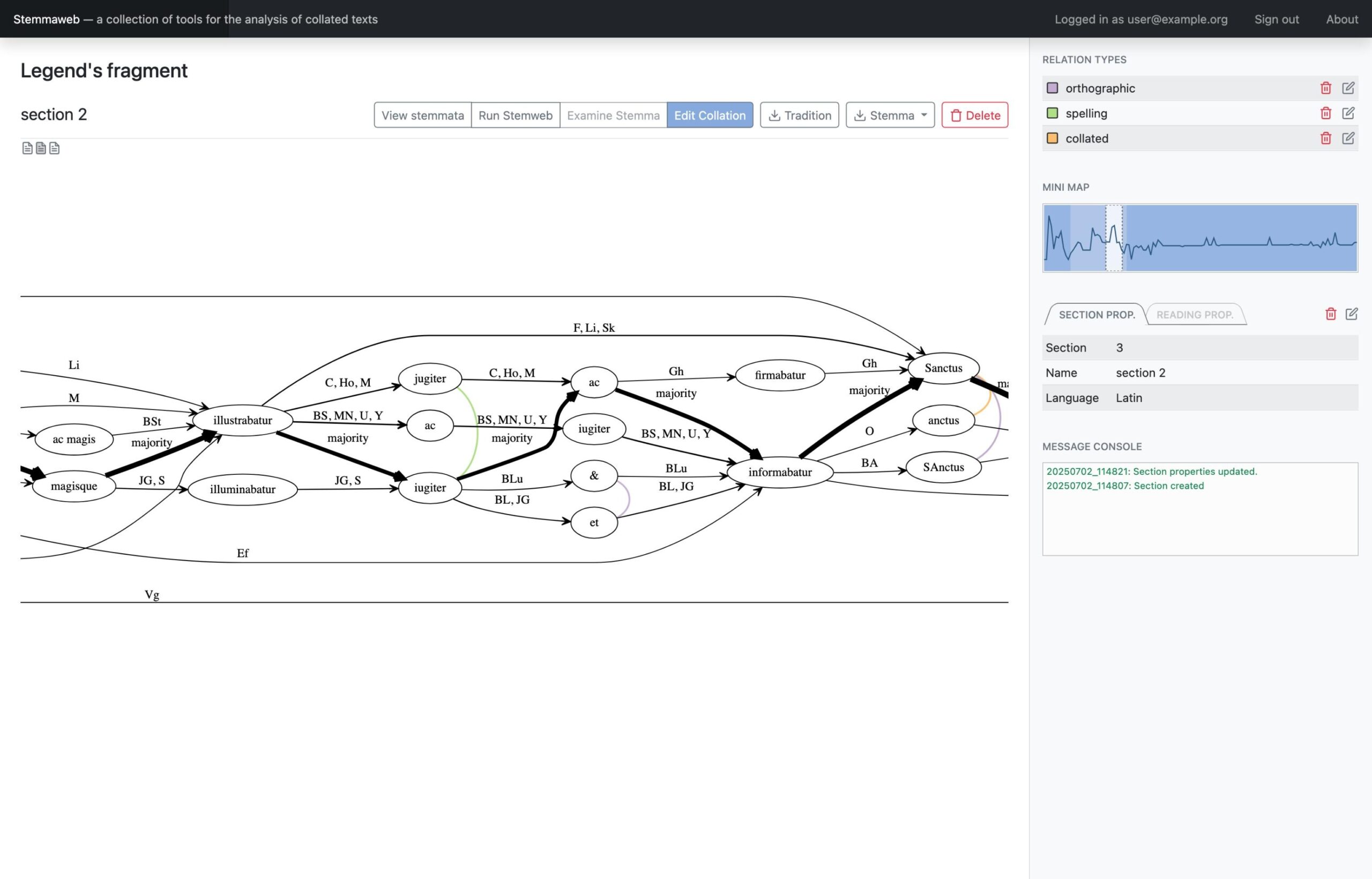
- Ingestion of collated text from several supported formats (CollateX JSON and GraphML, TEI export from Classical Text Editor, tabular alignment).
- Fully-featured editing and correction of uploaded collations.
- Customisable categorisation of variant types for each text tradition.
- Normalisation of the text according to categories of variant.
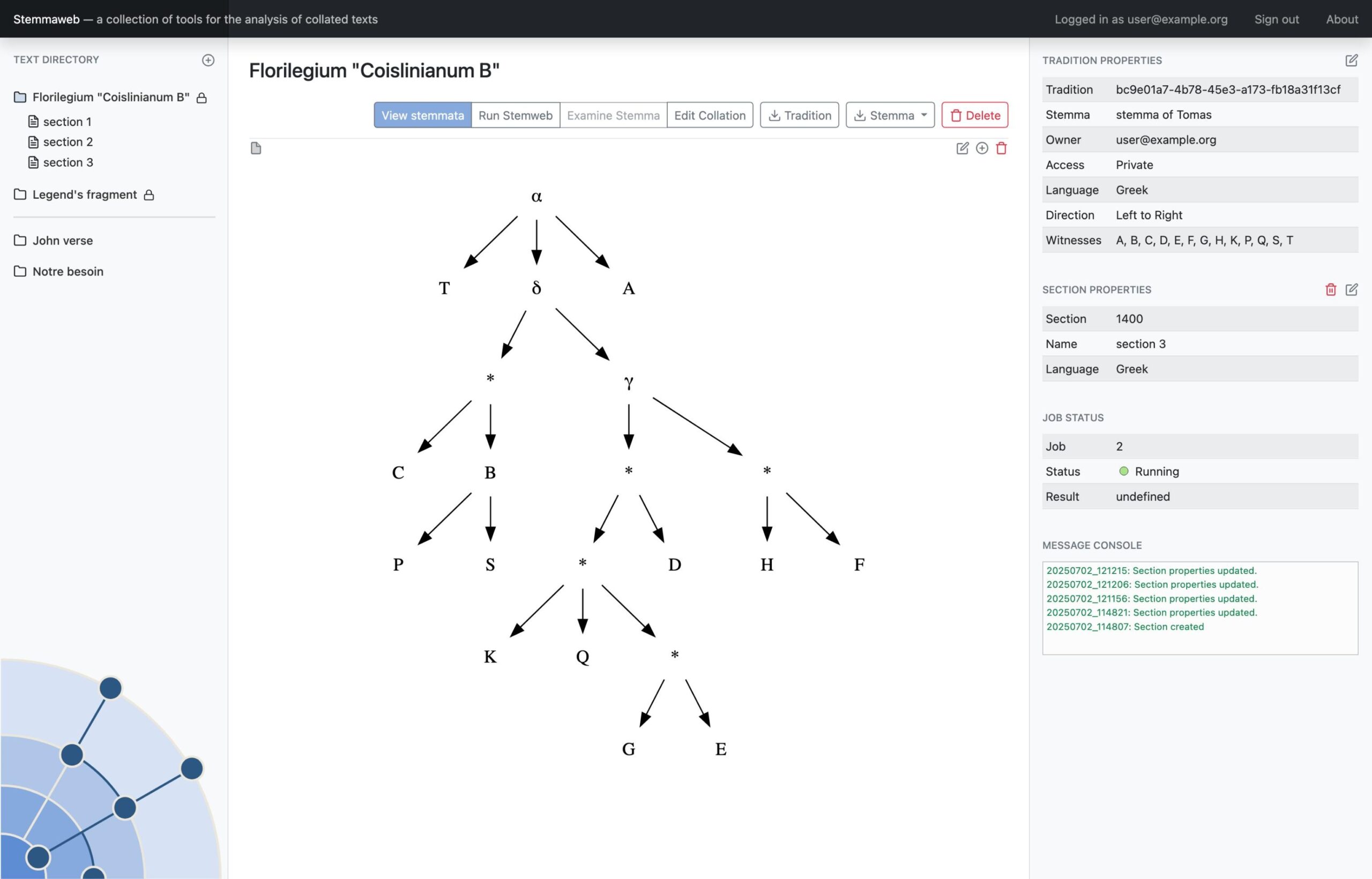
- Stemma definition and generation with all Stemweb-supported algorithms.
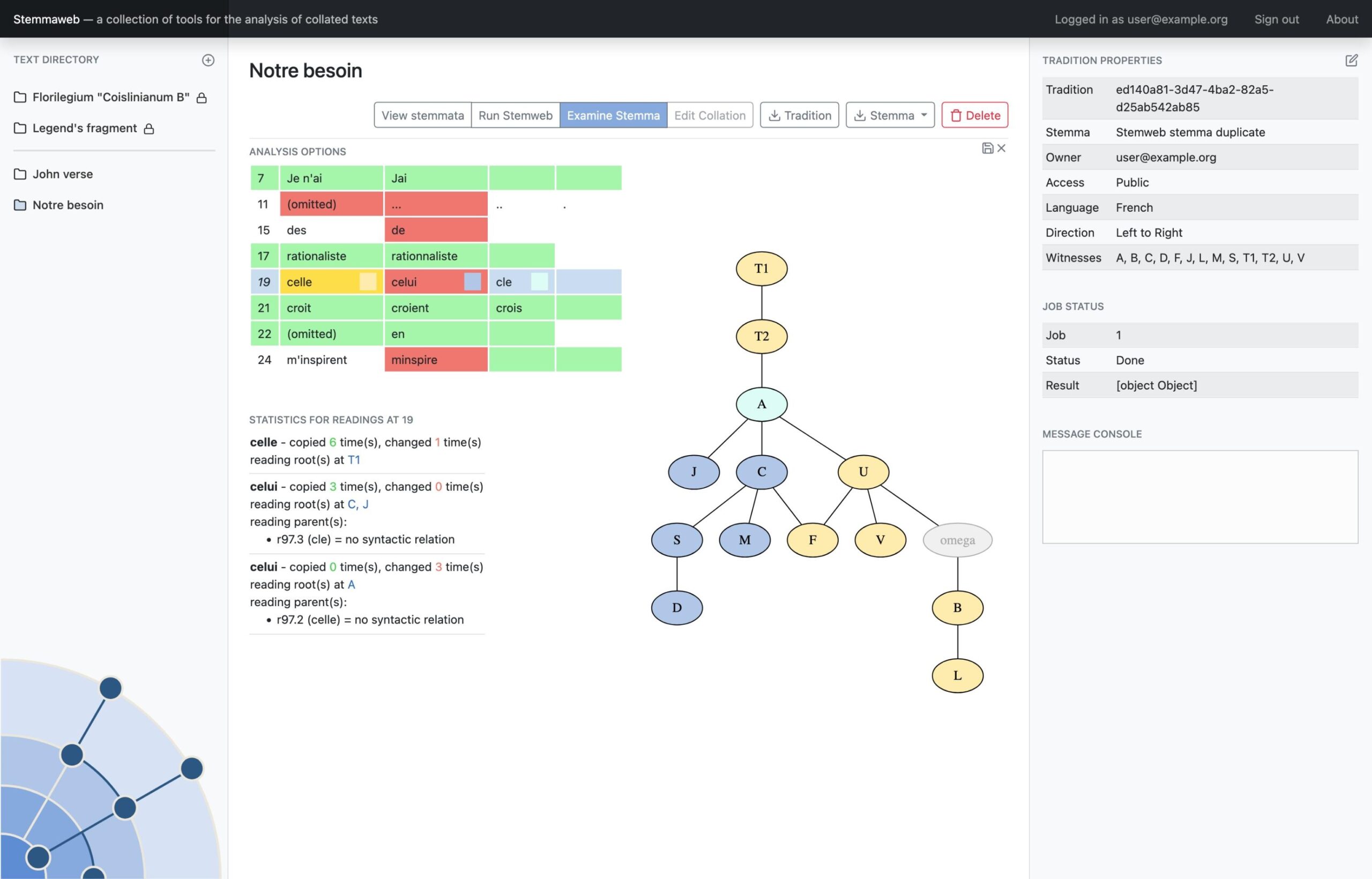
- Examination of variation according to a particular stemma with the StExaminer.
- Specification of lemma readings and of emendations to the text.
- Automated lemmatisation and re-lemmatisation of a text tradition according to a selected stemma.
- Export of the text data to various open formats, including TEI parallel segmentation.
Development and testing workflow
We have also taken the opportunity to set up a robust development workflow, which adopts current best practices supported by Github tooling. A front-end test suite based on the Cypress testing framework is executed via Github Actions as part of a continuous integration pipeline; all pull requests must contain a list of tests that need to be implemented in order to verify the functionality within the request. Our end-to-end tests thus check that features continue to work as intended for the user even as the interface evolves. The development and testing pipeline also ensures that future changes in library support will be noticed and accommodated promptly.